Where Are The Libertarians?
…or…
The Tough Road Ahead for Howard Schultz
…or…
My Preconceived Notions Are Shattered
At the risk of losing half my readers in the first paragraph, I’ll share my political views. Generally, I believe in “free people and free markets.” That makes me a small-L libertarian. I stress “generally” does not mean everywhere, all the time. I find it useful to think of, not a political spectrum from left to right, but a compass with four points. People have distinct views on social issues that may be separate from their views on government’s role in the economy. The traditional political party platforms don’t capture that nuance. There is no room in the Democratic or Republican Parties for a right-to-life advocate who also wants universal health care, for example.
I have always assumed that, free of the shackles of traditional party labels, most Americans are tolerant of people with different lifestyles than their own. At the same time we mostly believe that private markets do a better job of allocating resources than government bureaucrats. YOU may not believe that but, as I said, that’s been my working assumption about most people. We lean libertarian under the skin.
Last week the founder of Starbucks announced his candidacy for President. This article in the New York Times suggested he has centrist appeal but that group might be “smaller than he realizes.” The article goes on to say:
These dissatisfied centrist voters fit the profile of affluent, socially moderate and fiscally conservative suburban voters. They are twice as likely to make more than $100,000 per year than voters who have a favorable view of a party, and 78 percent of these voters say Democrats “too often see government as the only way to solve problems.”
Mr. Schultz could certainly play to these voters, but it is not a particularly electorally fruitful group. In an analysis of the Voter Study Group, Lee Drutman, a political scientist, found that just 4 percent of voters were conservative on economic issues and liberal on cultural issues. In comparison, populists represented 29 percent of the 2018 electorate. Mr. Schultz’s candidacy might be the reverse of Mr. Perot’s, but Mr. Perot’s pitch probably had broader appeal.
Then I read the article by Lee Drutman referenced by The Times and was discouraged to see little support for libertarian positioning in the 2016 survey of voters by YouGov.com. Fortunately, the raw data is all available. This survey was updated in December 2018 and the data can be found here..
This survey looks like the perfect opportunity to see if my sensibilities are widely shared. In the process we will learn how to pick apart the VOTER data set. The huge number of questions are a rich trove for exploration by any political junkie. The survey results are a CSV file in a zipped package. The file is in my Github repo but, as a matter of courtesy, please request it from The Voter Study Group, as their usage terms stipulate. It’s free and easy.
A quick disclaimer: This is a recreational excercise. I am not a professional scientist, social, data or otherwise. This is “outsider” science. I welcome critiques from people who know what they are talking about.
Start by loading in the raw data. As a matter of style, I like to keep a raw data frame in pristine form and manipulate a copy so if I mess up I can always restart the data munging from the same base. If memory allows, additional intermediate versions might be helpful. As always, we will be working in the Tidyverse dialect.
# load libararies and files
library(tidyverse)
library(knitr)
voter_18_raw <- read_csv("data/VOTER_Survey_April18_Release1.csv")Choose the Questions to Use
While Mr. Drutman’s analysis of the survey did not show many libertarian-leaning voters, I hoped that selecting my own set of questions narrowly focused on the relevant issues might provide more support for my point of view. So, to be honest, I went into this with a preconceived notion of the answer I wanted to get. Beware.
Out of the dozens of questions the survey asked, I pulled out those which seemed to go to the separate dimensions of the conservative/liberal spectrum. The questions involved:
Fiscal Issues
- Trust of the government in Washington
- Amount of regulation of business by the government
- Importance of reducing the federal deficit
- Role of government in economy
- Desired third party position on economic issues
Social Issues
- Difficulty of foreigners to immigrate to US
- Gender Roles “Women belong in the kitchen!”
- Views about the holy scriptures of own religion, literal truth?
- Opinion on gay marriage
- Public restroom usage of transgender people
- View on abortion
- Desired third party position on social and cultural issues
Pull Out Demographic Features
Now we massage the raw data a few ways. First we gather() the data to group the interesting demographic features as separate variables and tidy up all the remaining questions and answers into two variables.
voter_18<- gather(voter_18_raw,"question","answer",
-caseid,
-pid3_2018,
-race_2018,
-gender_2018,
-faminc_new_2018,
-inputstate_2018
) %>%
as_tibble() %>%
filter(!is.na(caseid)) %>%
filter(!is.na(answer)) %>%
distinct()
# labels of the questions we want to keep, with a (f)iscal or (s)ocial tag
questions_to_keep <- read_csv(
"axis_flag,question\n
f,trustgovt_2018\n
s,immi_makedifficult_2018\n
f,tax_goal_federal_2018\n
f,govt_reg_2016\n
s,sexism1_2018\n
s,holy_2018\n
s,gaymar_2016\n
s,abortview3_2016\n
s,third_soc_2018\n
f,third_econ_2018\n
f,gvmt_involment_2016\n",trim_ws=T)
voter_18 <- voter_18 %>% filter(question %in% questions_to_keep$question)
voter_18 <- voter_18 %>% mutate(answer=as.numeric(answer))
# make demographic variables factors
voter_18 <- voter_18 %>%
mutate(caseid =as.character(caseid)) %>%
mutate(gender_2018=as.factor(gender_2018)) %>%
mutate(race_2018=as.factor(race_2018)) %>%
mutate(faminc_new_2018=as.factor(faminc_new_2018)) %>%
mutate(pid3_2018=as.factor(pid3_2018)) %>%
rename(party_2018=pid3_2018) %>%
rename(state_2018=inputstate_2018) %>%
rename(income_2018=faminc_new_2018)
#map state numbers to state abbreviations
state_plus <- c(state.abb[1:8],"DC",state.abb[9:50])
voter_18$state_2018 <- factor(voter_18$state_2018)
levels(voter_18$state_2018) <- state_plus
levels(voter_18$gender_2018) <- c("Male","Female")
levels(voter_18$race_2018) <- c("White","Black","Hispanic",
"Asian","Native Amerian","Mixed",
"Other","Middle Eastern")
levels(voter_18$party_2018) <- c("Democrat","Republican","Independent",
"Other","Not Sure")
#Make human-readable income column
income_key<-read_csv(
"Response,Label\n
1, Less than $10\n
2, $10 - $19\n
3, $20 - $29\n
4, $30 - $39\n
5, $40 - $49\n
6, $50 - $59\n
7, $60 - $69\n
8, $70 - $79\n
9, $80 - $99\n
10, $100 - $119\n
11, $120 - $149\n
12, $150 - $199\n
13, $200 - $249\n
14, $250 - $349\n
15, $350 - $499\n
16, $500 or more\n
97, Prefer not to say\n"
,col_types = "ff",trim_ws = TRUE)
voter_18 <- voter_18 %>% mutate(income_2018_000=income_2018)
levels(voter_18$income_2018_000)<-levels(income_key$Label)
# now make income_2018 continuous again, keeping income_2018_000 as a factor
# for labeling
# "Prefer not to say" (coded as 97) is set to NA.
voter_18 <- voter_18 %>% mutate(income_2018=ifelse(income_2018==97,NA,income_2018)) %>%
mutate(income_2018=as.numeric(income_2018))
voter_18[1:10,]## # A tibble: 10 x 9
## caseid gender_2018 race_2018 income_2018 party_2018 state_2018 question
## <chr> <fct> <fct> <dbl> <fct> <fct> <chr>
## 1 38248~ Female Hispanic 7 Democrat CA trustgo~
## 2 38216~ Female White 8 Republican AZ trustgo~
## 3 38216~ Male White 6 Independe~ WI trustgo~
## 4 38233~ Male White 7 Republican TX trustgo~
## 5 38248~ Female White 5 Democrat CA trustgo~
## 6 38329~ Male White NA Republican WI trustgo~
## 7 38222~ Female White 3 Democrat VT trustgo~
## 8 38233~ Female White 12 Independe~ FL trustgo~
## 9 38226~ Female White 9 Democrat AZ trustgo~
## 10 38216~ Female White 6 Independe~ NE trustgo~
## # ... with 2 more variables: answer <dbl>, income_2018_000 <fct># We did a lot of work. Save it.
save(voter_18,file="data/voter_18.rdata")
# free up 30mb of memory
rm(voter_18_raw)Look at some of the demographics.
demographics <- voter_18 %>%
distinct(caseid,.keep_all = TRUE) %>%
select(-question,-answer)
demographics %>% group_by(gender_2018) %>%
summarise(count=n()) %>% kable()| gender_2018 | count |
|---|---|
| Male | 2762 |
| Female | 3239 |
demographics %>%
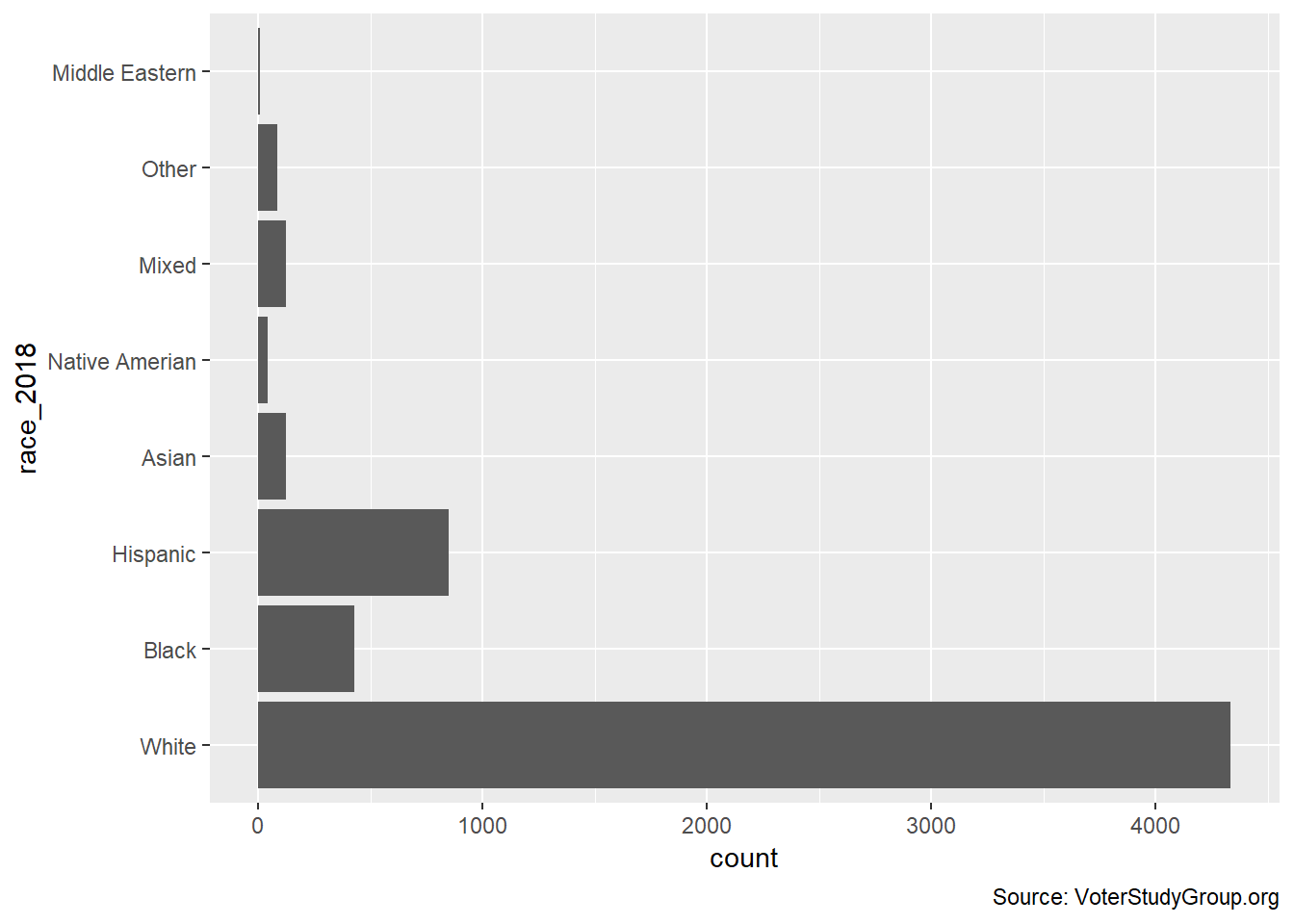
ggplot(aes(race_2018))+geom_bar()+coord_flip() +
labs(caption = "Source: VoterStudyGroup.org")
Rescale Answers for Consistency
The final step in massaging the data is to rescale all the question answers to between one and minus one, interpreted as liberal to conservative, respectively, in two dimensions. “Don’t know” (usually coded as 8) is treated as neutral (zero). If the question is “fiscal”, set “social” to NA and vice versa.
#add two new columns to hold scaled answers.
voter_18_scaled<-voter_18 %>% mutate(fiscal=NA,social=NA)
# -1 is fiscal liberal
voter_18_scaled <- voter_18_scaled %>%
mutate(fiscal=ifelse(question=="trustgovt_2018",-(answer-2),fiscal))
# -1 is social liberal
voter_18_scaled <- voter_18_scaled %>%
mutate(social=ifelse(question=="immi_makedifficult_2018",(answer-3)*0.5,social))
voter_18_scaled <- voter_18_scaled %>%
mutate(social=ifelse(question=="immi_makedifficult_2018",
ifelse(answer==8,0,social),social))
# -1 is fiscal liberal
voter_18_scaled <- voter_18_scaled %>%
mutate(fiscal=ifelse(question=="tax_goal_federal_2018",(answer-2.5)*-(2/3),fiscal))
# -1 is fiscal liberal
voter_18_scaled <- voter_18_scaled %>%
mutate(fiscal=ifelse(question=="govt_reg_2016",-(answer-2),fiscal))
voter_18_scaled <- voter_18_scaled %>%
mutate(fiscal=ifelse(question=="govt_reg_2016",
ifelse(answer==8,0,fiscal),fiscal))
# -1 is social liberal
voter_18_scaled <- voter_18_scaled %>%
mutate(social=ifelse(question=="sexism1_2018",(answer-2.5)*-(2/3),social))
# -1 is social liberal
voter_18_scaled <- voter_18_scaled %>%
mutate(social=ifelse(question=="holy_2018",-(answer-2),social))
# -1 is social liberal
voter_18_scaled <- voter_18_scaled %>%
mutate(social=ifelse(question=="gaymar_2016",(answer-1.5)*2,social))
voter_18_scaled <- voter_18_scaled %>%
mutate(social=ifelse(question=="gaymar_2016",
ifelse(answer==8,0,social),social))
# -1 is social liberal
voter_18_scaled <- voter_18_scaled %>%
mutate(social=ifelse(question=="view_transgender_2016",(answer-1.5)*2,social))
voter_18_scaled <- voter_18_scaled %>%
mutate(social=ifelse(question=="view_transgender_2016",
ifelse(answer==8,0,social),social))
# -1 is social liberal
voter_18_scaled <- voter_18_scaled %>%
mutate(social=ifelse(question=="abortview3_2016",(answer-2),social))
voter_18_scaled <- voter_18_scaled %>%
mutate(social=ifelse(question=="abortview3_2016",
ifelse(answer==8,0,social),social))
# -1 is social liberal
voter_18_scaled <- voter_18_scaled %>%
mutate(social=ifelse(question=="third_soc_2018",(answer-3)*0.5,social))
# -1 is fiscal liberal
voter_18_scaled <- voter_18_scaled %>%
mutate(fiscal=ifelse(question=="third_econ_2018",(answer-3)*0.5,fiscal))
# -1 is fiscal liberal
voter_18_scaled <- voter_18_scaled %>%
mutate(fiscal=ifelse(question=="gvmt_involment_2016",(answer-1),fiscal))
voter_18_scaled <- voter_18_scaled %>%
mutate(fiscal=ifelse(question=="gvmt_involment_2016",
ifelse(answer==8,0,fiscal),fiscal))
# We did a lot of work. Save it.
save(voter_18_scaled,file="data/voter_18_scaled.rdata")
Now we have values that we can aggregate for each question. They are all normalized and given equal weight. Should each question be given equal weight? I don’t know, but now we can compute average scores for each caseid (each one is one voter) . We also add the demographic features to each observation. So now every caseid in the survey is assigned a separate fiscal and social temperament score.
scores <- voter_18_scaled %>%
group_by(caseid) %>%
summarise(social=mean(social,na.rm = T),fiscal=mean(fiscal,na.rm = T)) %>%
left_join(demographics) #Add demographics to scoresLet’s start off at the highest level. What are the mean values for each dimension?
mean_social <- mean(scores$social,na.rm = T)
mean_fiscal <- mean(scores$fiscal,na.rm = T)
print(paste("Mean Fiscal=",round(mean_fiscal,2)))## [1] "Mean Fiscal= 0.06"print(paste("Mean Social=",round(mean_social,2)))## [1] "Mean Social= -0.16"Well that is an encouraging start. The signs are in the libertarian quadrant, anyway, but are they statistically significant? Specifically, can we reject the hypothesis that the true mean is greater than zero for social, and less than zero for fiscal?
t_s <-t.test(scores$social,mu=0,conf.level = 0.95,alternative="greater") %>% broom::tidy()
t_f <-t.test(scores$fiscal,mu=0,conf.level = 0.95,alternative="less") %>% broom::tidy()
t_both<-bind_cols(Dimension=c("Social","Fiscal"),bind_rows(t_s,t_f)) %>%
select(Dimension,estimate,statistic,conf99.low=conf.low,conf99.high=conf.high)
t_both## # A tibble: 2 x 5
## Dimension estimate statistic conf99.low conf99.high
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Social -0.157 -24.6 -0.167 Inf
## 2 Fiscal 0.0585 11.4 -Inf 0.0669With such a large sample size we can be pretty confident that the true mean is close to the sample mean and therefore leans libertarian. Alas, that is not enough to form an opinion. The magnitudes are still very small and a slight relative shift in the aggregate may not support my hypothesis that most people have a libertarian bias when you break down the issues. Further, we haven’t even touched on the survey methodology. It is an online survey and therefore means the respondents have computers and are facile with internet access. That population is closer and closer to “everyone” with each passing day but is still not universal.
With our data all cleaned up, let’s look at some pictures!
gg <- ggplot(scores,aes(fiscal,social)) + geom_point()
gg <- gg + geom_jitter(width=0.05,height=0.05)
gg <- gg + geom_hline(yintercept = 0,color="red")
gg <- gg + geom_vline(xintercept = 0,color="red")
gg <- gg + annotate("text",label=c("Libertarian"),x=0.9,y=-0.9,color="red")
gg <- gg + labs(title="Separation of Social and Fiscal Values",
y = "Social Score (Lower=More Liberal)",
x = "Fiscal Score (Lower=More Liberal)",
caption = "Source: VoterStudyGroup.org")
gg <- gg + annotate("text",x=-0.7,y=1.0,color="red",
label=paste("Mean Fiscal=",round(mean_fiscal,2),
"Mean Social=",round(mean_social,2)))
gg <- gg + geom_smooth(method="lm")
gg
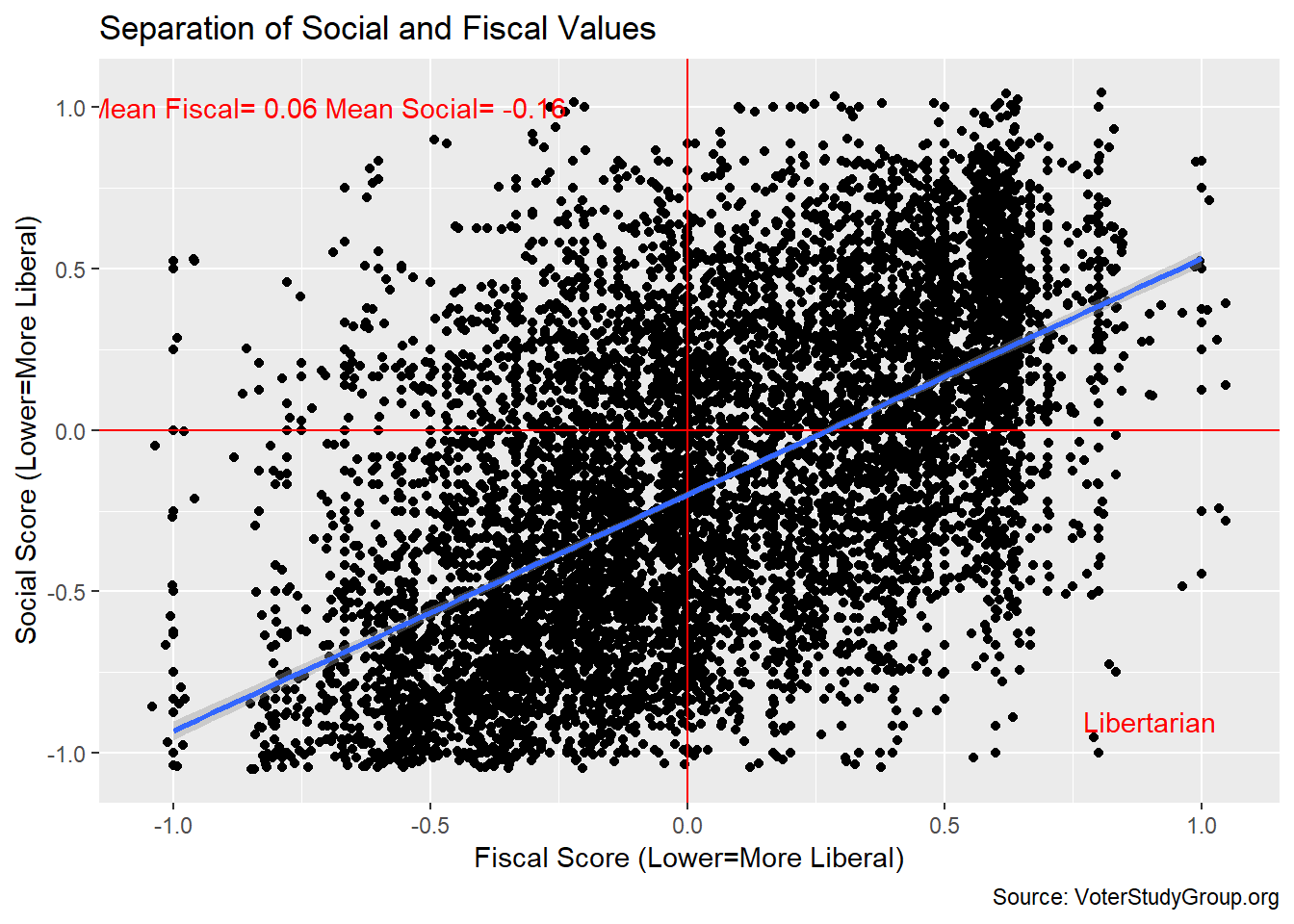
The first thing to note is the values are all over the chart. We’ve added some random “jitter” noise to the position of each point with geom_jitter(). Otherwise, many of the points would overlap and obscure the density of the points. Even so, careful scrutiny of of the standard error range around the regression line shows that a huge number of points lie very close to the line.
Sadly, for a libertarian, the scores tend to line up close to the 45 degree axis, which means people who are more socially conservative are more likely to be fiscally conservative as well. The libertarian quadrant is the lower right, which is more sparsely populated.
lm(scores$social~scores$fiscal) %>% broom::tidy()## # A tibble: 2 x 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) -0.200 0.00518 -38.5 5.39e-290
## 2 scores$fiscal 0.732 0.0129 56.7 0.Let’s count voter incidence in each quadrant.
#call zero scores "Neutral"
scores <- scores %>%
mutate(fiscal_label=cut(scores$fiscal,c(-1,-0.0001,0.0001,1),
labels=c("Liberal","Neutral","Conservative"))) %>%
mutate(social_label=cut(scores$social,c(-1,-0.01,0.01,1),
labels=c("Liberal","Neutral","Conservative")))
xtabs(~fiscal_label+social_label,scores) %>%
as_tibble() %>%
arrange(desc(n)) %>%
filter(fiscal_label != "Neutral",social_label != "Neutral")## # A tibble: 4 x 3
## fiscal_label social_label n
## <chr> <chr> <int>
## 1 Liberal Liberal 1903
## 2 Conservative Conservative 1745
## 3 Conservative Liberal 1046
## 4 Liberal Conservative 387The largest quadrant is Liberal/Liberal followed by Conservative/Conservative. Leaving out the neutral axes, the libertarian quadrant (liberal social, conservative fiscal) is third with a respectable number of respondents. This is about 18% of the sample, far more than the 4% Mr. Drutman found. The liberal fiscal, conservative social quadrant, which is populist I suppose, includes the fewest voters.
This is suggestive of traditional party platforms so how does this look broken out by party?
gg <-ggplot(scores,aes(fiscal,social,color=party_2018))+geom_point()
gg <- gg + geom_jitter(width=0.05,height=0.05)
gg <- gg + geom_hline(yintercept = 0)
gg <- gg + geom_vline(xintercept = 0)
gg <- gg + annotate("text",label=c("Libertarian"),x=0.9,y=-0.9)
gg <- gg + scale_color_manual(values=c(Republican='#e41a1c',
Democrat='#377eb8',
Independent='#4daf4a',
Other='#984ea3',
`Not Sure`='#ff7f00'))
gg <- gg + labs(title="Party Lines Align With Temperament",
y = "Social Score (Lower=More Liberal)",
x = "Fiscal Score (Lower=More Liberal)",
caption = "Source: VoterStudyGroup.org")
gg
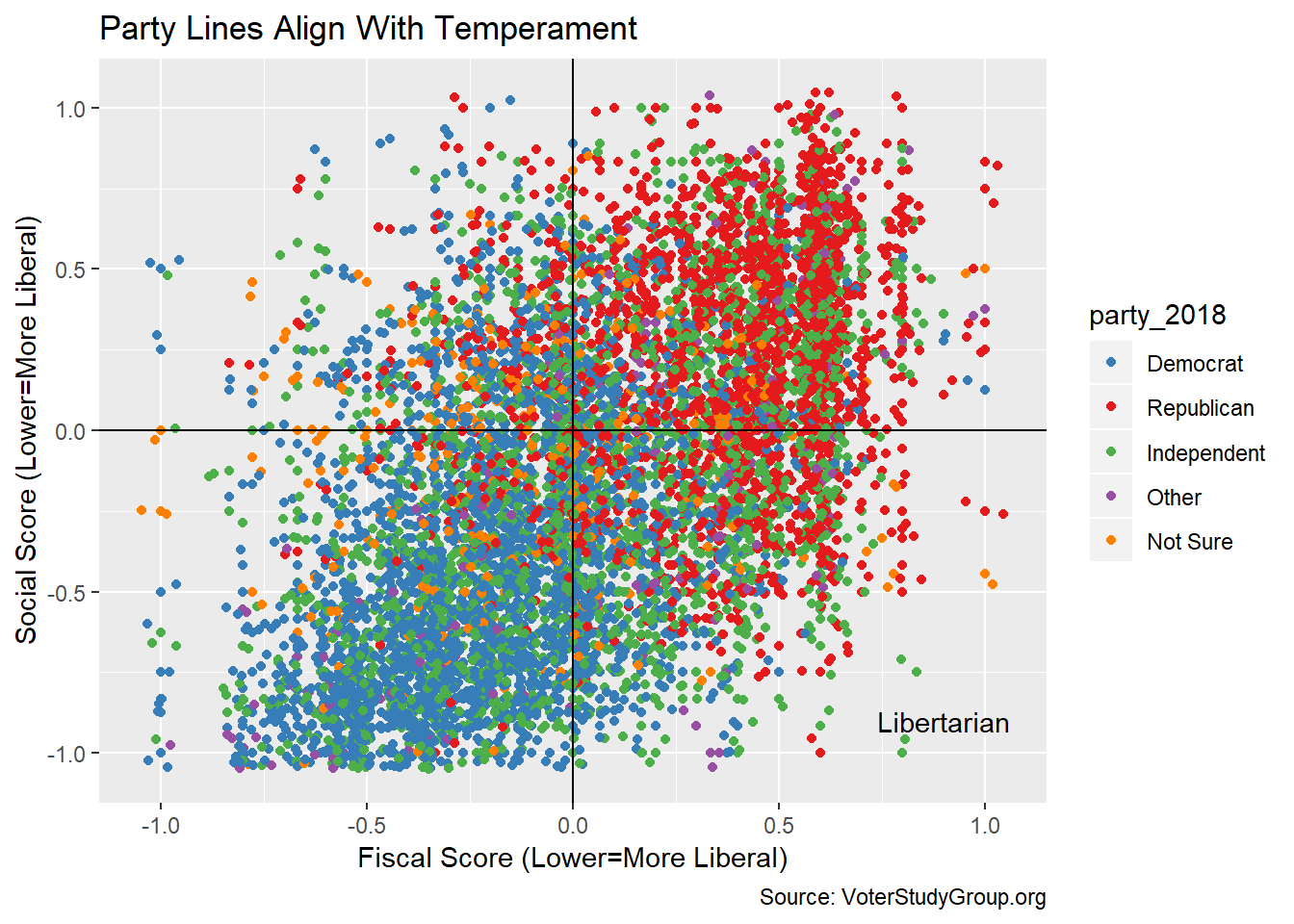
There is a clear bifurcation around party, which is exactly what we’d expect.
The survey respondents are overwhelmingly white. What does the plot look like if we remove them from data set?
gg <- scores %>% filter(race_2018 != "White") %>%
ggplot(aes(fiscal,social,color=race_2018))+geom_point()
gg <- gg + geom_jitter(width=0.05,height=0.05)
gg <- gg + geom_hline(yintercept = 0)
gg <- gg + geom_vline(xintercept = 0)
gg <- gg + annotate("text",label=c("Libertarian"),x=0.9,y=-0.9)
gg <- gg + labs(title="Minorities Are Not Too Different from Whites",
y = "Social Score (Lower=More Liberal)",
x = "Fiscal Score (Lower=More Liberal)",
caption = "Source: VoterStudyGroup.org")
gg
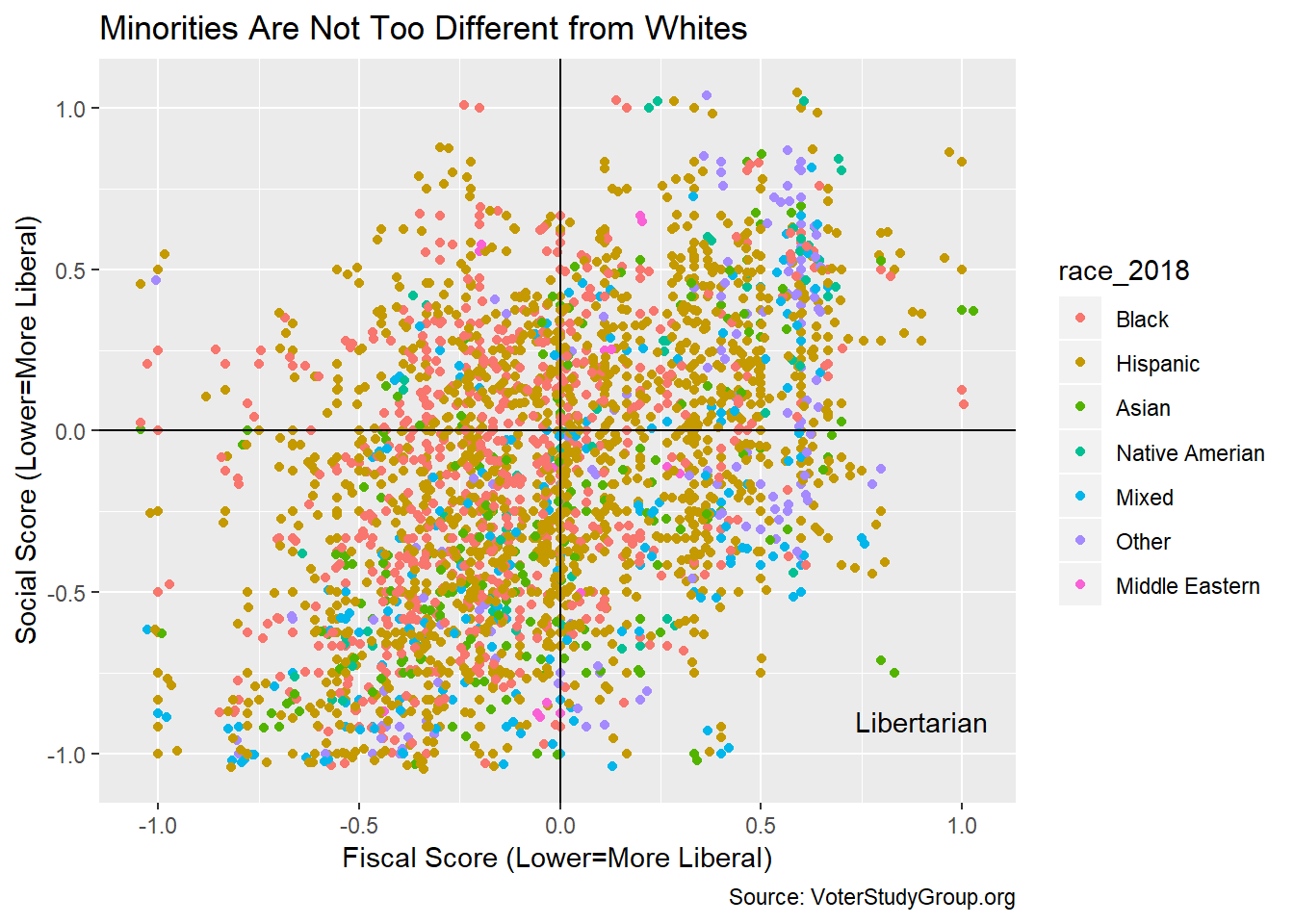
The sub sample above looks very similar to the whole data set. Black voters do skew more to the Liberal/Liberal side but Hispanic voters do not.
Let’s meet some individuals. Who are the folks who show strong libertarian sentiments (greater than 0.5 social, less than -0.5 fiscal), all nineteen of them?
scores %>% filter(fiscal < (0.5),social > (-0.5)) %>% select(gender_2018,race_2018,party_2018,income_2018_000,state_2018)## # A tibble: 2,984 x 5
## gender_2018 race_2018 party_2018 income_2018_000 state_2018
## <fct> <fct> <fct> <fct> <fct>
## 1 Male White Independent $150 - $199 MI
## 2 Male White Independent $60 - $69 SD
## 3 Male White Republican $100 - $119 OK
## 4 Female White Republican $10 - $19 WI
## 5 Male White Republican $30 - $39 CA
## 6 Female White Republican $40 - $49 WA
## 7 Female White Republican $10 - $19 IN
## 8 Female Hispanic Democrat $50 - $59 NY
## 9 Female White Independent $30 - $39 MD
## 10 Female White Independent $120 - $149 MA
## # ... with 2,974 more rowsThese folks are almost all white, but our set is a tiny sub sample so I doubt any generalizations are significant. There is only one Democrat in the bunch. They are not rich and they’re spread around the country. They are men and women.
We have a number of additional demographic variables but let’s just look at one more of them. How do scores look conditioned on income?
gg <- scores %>% filter(!is.na(income_2018)) %>%
ggplot(aes(income_2018_000,fiscal,group=income_2018)) + geom_boxplot()
gg <- gg + coord_flip() + theme(axis.text.x = element_text(angle=-90))
gg <- gg + geom_hline(yintercept = 0,color="red")
gg <- gg + labs(title="Higher Income Does Not Make a Fiscal Conservative",
x = "Annual Income ($000)",
y = "Fiscal Score (Lower=More Liberal)",
caption = "Source: VoterStudyGroup.org")
gg
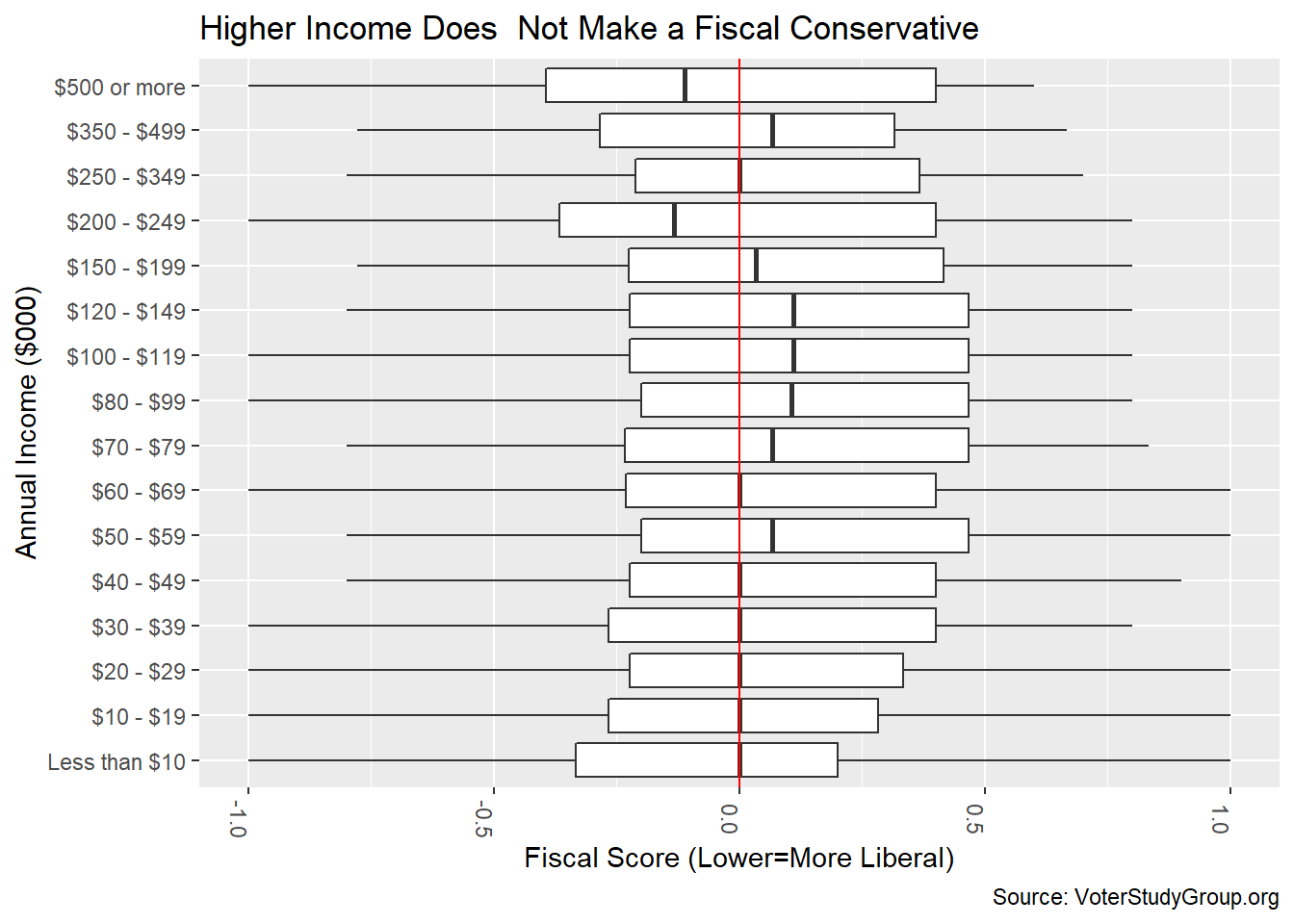
Surprisingly, to me, there is no trend to prefer less government as income rises. The desire for government involvement in the economy is close to neutral across all income cohorts. Note, I did not include any tax questions for this measure. People are happy to favor higher taxes on anybody who makes more money than they do.
gg <- scores %>% filter(!is.na(income_2018)) %>%
ggplot(aes(income_2018_000,social,group=income_2018))+ geom_boxplot()
gg <- gg + coord_flip() + theme(axis.text.x = element_text(angle=-90))
gg <- gg + geom_hline(yintercept = 0,color="red")
gg <- gg + labs(title="Higher Income Does Make One More Socially Liberal",
x = "Annual Income ($000)",
y = "Social Score (Lower=More Liberal)",
caption = "Source: VoterStudyGroup.org")
gg
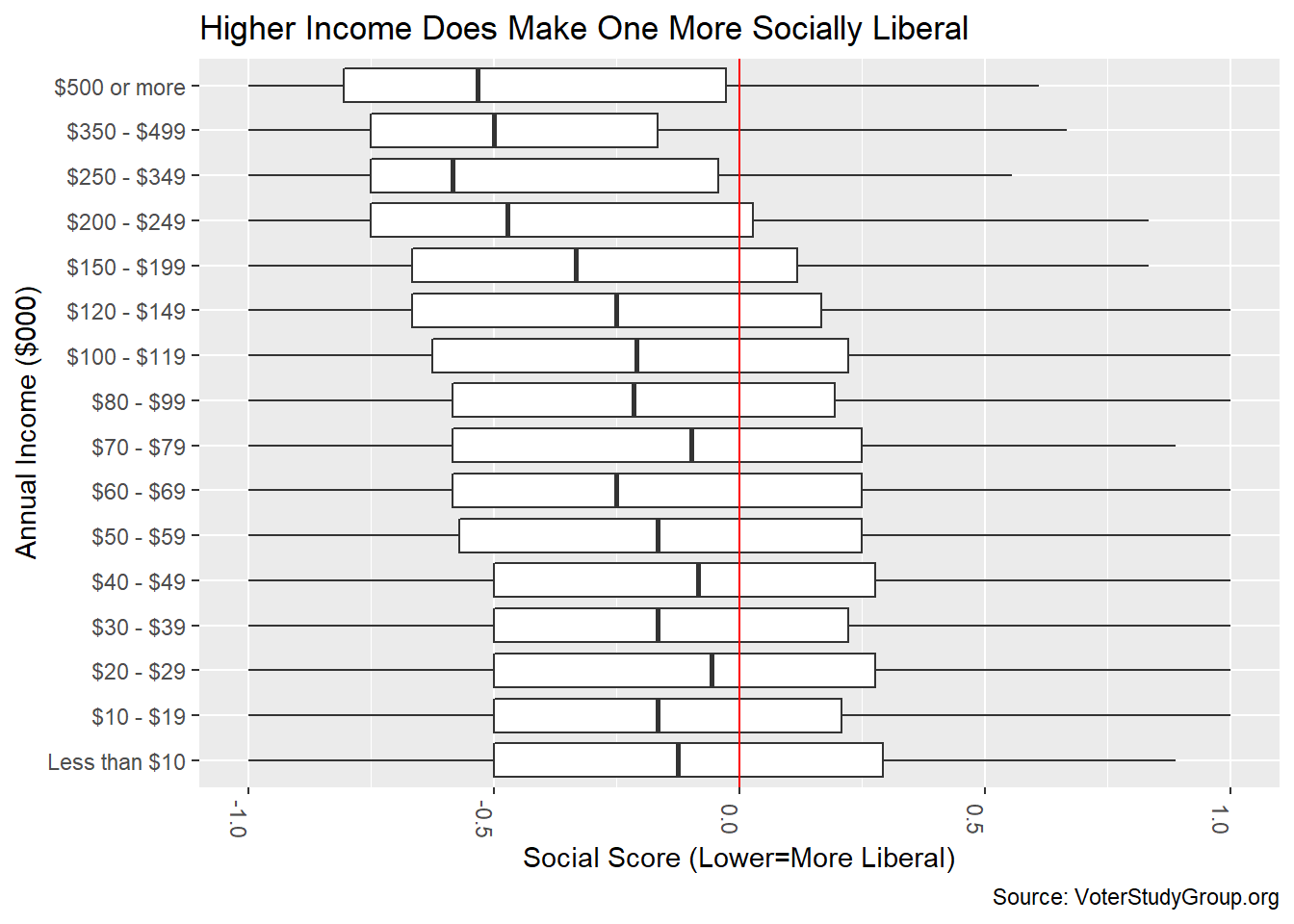
There is some association with more socially liberal views as income rises. The richer you are, the more tolerant you are of other’s lifestyles, I guess. During the 2016 election there was some questioning around why poor people (mainly rural whites) voted “against their economic interest.” This suggests that voting WITH their conservative social interests was more important (I am not saying that our current president embodies conservative social values). Most pundits put a racial angle on this. In all income cohorts the median voter is at least a shade liberal on social issues.
How Much Does Location Matter?
Let’s look at average scores by state. To remind us of the influence that larger states have on the overall numbers we’ll grab population data from the Census Bureau. There are a number of R packages to access the census API but those are more than we need and require an API key. Here, we’ll just grab a summary CSV file from the web site.
# download population summary from census bureau
state_pop_raw<-read_csv("https://www2.census.gov/programs-surveys/popest/datasets/2010-2018/national/totals/nst-est2018-alldata.csv")## Parsed with column specification:
## cols(
## .default = col_double(),
## SUMLEV = col_character(),
## REGION = col_character(),
## DIVISION = col_character(),
## STATE = col_character(),
## NAME = col_character()
## )## See spec(...) for full column specifications.save(state_pop_raw,file="data/state_pop_raw.rdata")
load("data/state_pop_raw.rdata")
# filter to keep only state level data and add abbreviations
# manually insert District of Columbia as a state
state_pop <- state_pop_raw %>%
transmute(state=NAME,population_2018=POPESTIMATE2018) %>%
filter(state %in% c(state.name,"District of Columbia")) %>%
bind_cols(state_2018=as_factor(state_plus))
gg <- scores %>% group_by(state_2018) %>%
summarize(fiscal=mean(fiscal,na.rm = T),social=mean(social,na.rm = T)) %>%
left_join(state_pop, by = "state_2018") %>%
ggplot(aes(fiscal,social)) + geom_point(aes(color=population_2018,
size=population_2018))
gg <- gg + ggrepel::geom_text_repel(aes(label=state_2018))
gg <- gg + scale_size(trans="log10",
labels=c("0","1 mm","3 mm","10 mm","30 mm","More"))
gg <- gg + scale_color_gradient(trans="log10",
labels=c("0","1 mm","3 mm","10 mm","30 mm","More"))
gg <- gg + geom_hline(yintercept = 0)
gg <- gg + geom_vline(xintercept = 0)
gg <- gg + annotate("text",label=c("Libertarian"),x=0.15,y=-0.4)
gg <- gg + labs(title="Separation of Social and Fiscal Values",
y = "Social Score (Lower=More Liberal)",
x = "Fiscal Score (Lower=More Liberal)",
caption = "Source: VoterStudyGroup.org")
gg
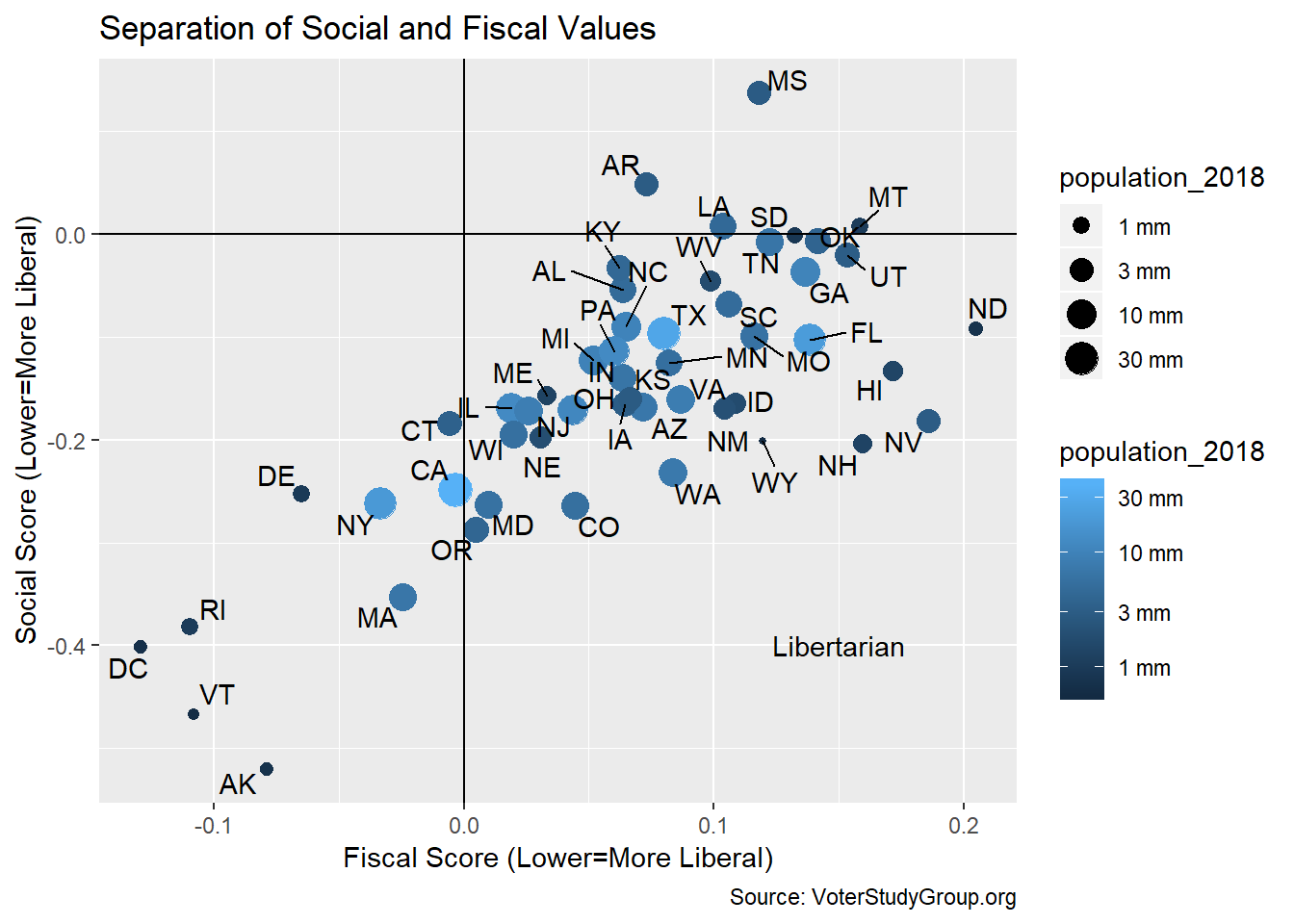
If I had created this chart first I might have been excited. It shows that the average voter in most states is in the libertarian quadrant. That is NOT the same thing as saying most voters in the “libertarian” states are libertarian. We already showed that the vast majority of voters fall outside the libertarian quadrant. Still, there are some interesting things to note. The fiscal sentiments of New Hampshire voters are far different than their Vermont neighbors. I don’t see Bernie Sanders sporting this license plate:

Live Free or Die
By the way, I wish I knew how to get color and size combined into one legend.
My Last Attempt at Validation
I went through the YouGov.com survey and picked out the questions I feel are relevant, a highly subjective exercise. Even so,the results do not support my belief that maybe a plurality of people have libertarian sensibilities. But there were hints that gave me some hope.
First, there is a clear yearning for a choice beyond the existing parties as this question shows:
In your view, do the Republican and Democratic parties do an adequate job of representing the American people, or do they do such a poor job that a third major party is needed?
| Count | Answer |
|---|---|
| 1,851 | Do adequate job |
| 4,036 | Third party is needed |
The fact that most people want another choice tells us nothing about what that choice is. Another question does seem to suggest libertarian economic sentiment in excess of what the number of Republicans might indicate:
In general, do you think there is too much or too little regulation of business by the government?
| Count | Answer |
|---|---|
| 3,473 | Too much |
| 1,628 | About the right amount |
| 1,999 | Too little |
| 871 | Don’t know |
Finally, there are two questions in the survey that go explicitly to the separation of social and fiscal values.
1. If you were to vote for a new third party, where would you like it to stand on social and cultural issues—like abortion and same-sex marriage?
2. If you were to vote for a new third party, where would you like it to stand on economic issues—like how much the government spends and how many services it provides?
The range of answers for both is:
| Score | Answer |
|---|---|
| 1.0 | More liberal than the Democratic Party |
| 0.5 | About where the Democratic Party is now |
| 0.0 | In between the Democratic Party and the Republican Party |
| -0.5 | About where the Republican Party is now |
| -1.0 | More conservative than the Republican Party |
Let’s re-do the scatter based on the answers to just those two questions. Since we are using only two questions with possible values of only 1,0 and minus 1, there are many more respondents than possible values. Again we add some random jitter to make the density clear. Every dot within each square is actually the same value. The result is a visual cross tab. I quite like the effect.
scores_narrow <- voter_18_scaled %>%
filter(str_detect(question,"third_")) %>%
group_by(caseid) %>%
summarise(social=mean(social,na.rm = T),fiscal=mean(fiscal,na.rm = T)) %>%
left_join(demographics)
gg <- ggplot(scores_narrow,aes(fiscal,social,color=party_2018))+geom_point() + geom_jitter()
gg <- gg + geom_hline(yintercept = 0)
gg <- gg + geom_vline(xintercept = 0)
gg <- gg + labs(title="What Kind of Third Party Would Voters Prefer?",
y = "Social Score (Lower=More Liberal)",
x = "Fiscal Score (Lower=More Liberal)",
caption = "Source: VoterStudyGroup.org")
gg <- gg + annotate("text",label=c("Libertarian"),x=0.9,y=-0.9,fontface="bold")
gg <- gg + annotate("text",label=c("Populist?"),x=-0.9,y=0.9,fontface="bold")
gg <- gg + annotate("text",label=c("Left of Democrats"),x=-0.9,y=-0.9,fontface="bold")
gg <- gg + annotate("text",
label=c("Right of Republicans"),
x=0.9,y=0.9,
fontface="bold")
gg <- gg + scale_color_manual(values=c(Republican='#e41a1c',
Democrat='#377eb8',
Independent='#4daf4a',
Other='#984ea3',
`Not Sure`='#ff7f00'))
gg
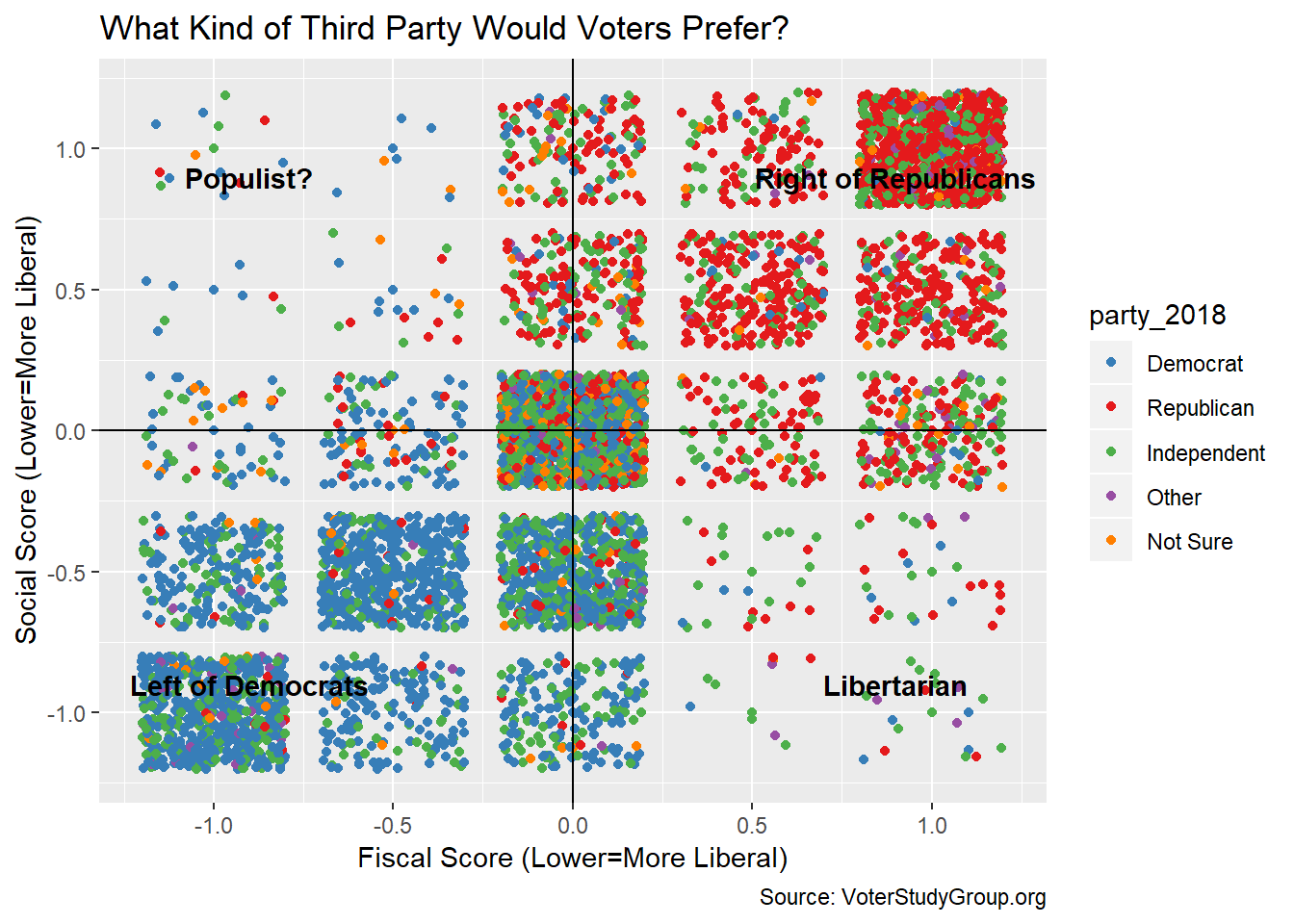
What I don’t like is the result. Contrary to my pre-conceived notion, it’s clear the American electorate is not crypto-libertarian. Rather, voters want a third party that is highly centrist or highly polarized along traditional liberal/conservative lines. This makes it unlikely that any single third party could be successful at the ballot box. Rather, both an extreme left-wing and an extreme right wing party could take votes away from the traditional parties. The Republican party is more hollowed out in its relative middle than the Democrats.
Could Howard Schulz be something of a spoiler from the center? Possibly. There are a large number of voters who would like an alternative that is less intrusive than the Democrats on economic issues and less intrusive than the Republicans on moral issues. I disagree with the Times’ assessment that, since there are so few absolute libertarians, Schulz will not find a base. As we see, there are many people who lean toward the center and away from the extremes within their parties, even if they are not libertarian, per se. But, far too many people are happy with the status quo or would like their party more on the left or right to make this likely as we see below.
tmp <-scores_narrow %>%
mutate(social_direction=cut(abs(social),breaks=c(-0.1,0.25,1.1),
labels=c("To the Center",
"Status Quo or More Extreme"))) %>%
mutate(fiscal_direction=cut(abs(fiscal),breaks=c(-0.1,0.25,1.1),
labels=c("To the Center",
"Status Quo or More Extreme")))
xtabs(~social_direction+fiscal_direction,tmp) %>% as_tibble() %>% kable()| social_direction | fiscal_direction | n |
|---|---|---|
| To the Center | To the Center | 1211 |
| Status Quo or More Extreme | To the Center | 1116 |
| To the Center | Status Quo or More Extreme | 496 |
| Status Quo or More Extreme | Status Quo or More Extreme | 3037 |
Conclusion
I started this exercise hoping to find some support for my personal views among the broader electorate. Sadly, I didn’t find much. The strongest statement I can make is there is a slight bias among both Republicans and Democrats for more centrist policies. But the fun of data science is finding things you didn’t expect and in validating or refuting hunches and feelings with good science. I know something today I didn’t know yesterday so I’ll call it a win!
UPDATE 2/8/2019: Based on feedback, I changed party colors and left/right positions to those most Americans are accomstomed to.
sessionInfo()## R version 3.5.1 (2018-07-02)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 10 x64 (build 17134)
##
## Matrix products: default
##
## locale:
## [1] LC_COLLATE=English_United States.1252
## [2] LC_CTYPE=English_United States.1252
## [3] LC_MONETARY=English_United States.1252
## [4] LC_NUMERIC=C
## [5] LC_TIME=English_United States.1252
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] bindrcpp_0.2.2 knitr_1.21 forcats_0.3.0 stringr_1.3.1
## [5] dplyr_0.7.8 purrr_0.3.0 readr_1.3.1 tidyr_0.8.2
## [9] tibble_2.0.1 ggplot2_3.1.0 tidyverse_1.2.1
##
## loaded via a namespace (and not attached):
## [1] tidyselect_0.2.5 xfun_0.4 haven_2.0.0 lattice_0.20-35
## [5] colorspace_1.4-0 generics_0.0.2 htmltools_0.3.6 yaml_2.2.0
## [9] utf8_1.1.4 rlang_0.3.1 pillar_1.3.1 glue_1.3.0
## [13] withr_2.1.2 modelr_0.1.2 readxl_1.2.0 bindr_0.1.1
## [17] plyr_1.8.4 munsell_0.5.0 blogdown_0.10 gtable_0.2.0
## [21] cellranger_1.1.0 rvest_0.3.2 evaluate_0.12 labeling_0.3
## [25] curl_3.3 fansi_0.4.0 highr_0.7 broom_0.5.1
## [29] Rcpp_1.0.0 scales_1.0.0 backports_1.1.3 jsonlite_1.6
## [33] hms_0.4.2 digest_0.6.18 stringi_1.2.4 ggrepel_0.8.0
## [37] bookdown_0.9 grid_3.5.1 cli_1.0.1 tools_3.5.1
## [41] magrittr_1.5 lazyeval_0.2.1 crayon_1.3.4 pkgconfig_2.0.2
## [45] xml2_1.2.0 lubridate_1.7.4 assertthat_0.2.0 rmarkdown_1.11
## [49] httr_1.4.0 rstudioapi_0.9.0 R6_2.3.0 nlme_3.1-137
## [53] compiler_3.5.1